
Deep Neural Networks on FPGA exploiting Partial Reconfiguration
Last month, I found that there’s some ‘AI hardware design contest’(AI 반도체 경연대회) going on. The contestants are given the neural network(NN) SW source code and what they need to do is implement it well on the FPGA. The final design will be evaluated based on its throughput, resource usage, design novelty, and whatever criterion the contestants think their designs excel on. It would have made more sense if the contestants come up with their own algorithms as HW and SW are tightly coupled, but the organizer must be afraid that the competition may end up in algorithm contest.
I thought, if I exploit Partial Reconfiguration in this context, I could probably win in novelty because I utilize FPGA’s special characteristic when FPGA is given to prototype ASIC. I am also ready to argue this approach is complementary if other teams come up with efficient implementations of each layer! Unfortunately, I wasn’t 100% buying the idea of exploiting PR in this context, so I ended up not participating in the design contest. Let me share some previous work done related this topic.
What is Partial Reconfiguration(PR)?
Partial Reconfiguration(PR) is a feature of a modern FPGAs that the part of the design is dynamically modified on runtime while the remaining of the design is still running. As can be seen in the figure below, the part of the design, which was initially configured with A1.bit, can be reconfigured with A2.bit, A3.bit or A4.bit while the “static” logic is unaffected. These bitstreams, A1.bit, A2.bit, A3.bit, and A4.bit are called partial bitstreams.

Partial Reconfiguration, Example
PR leads to an area reduction to the system that has mutually exclusive functionality. For instance, the design below originally has multiplexers with three functions to choose. In this ASIC style design, only one of the three functions is active at a time.
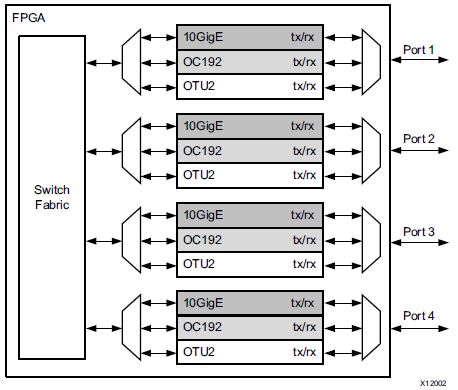
Network Switch WITHOUT Partial Reconfiguration [1]
On the other hand, PR removes this inefficiency by dynamically reconfiguring functions when needed. Another advantage is that, when Port 1 is reconfigured, others ports can run unaffected.
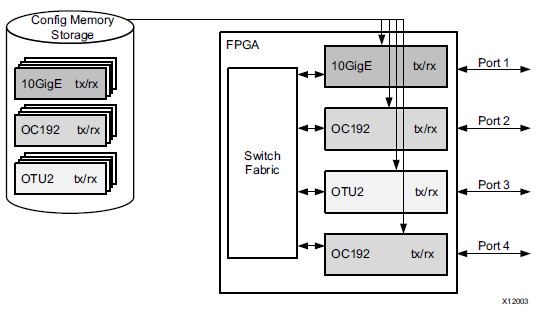
Network Switch WITH Partial Reconfiguration [1]
One may wonder, “If we don’t need Port2, Port3, and Port4 running when Port1 is reconfigured (so, giving up the advantage I just mentioned), do we need PR at all? Doesn’t FPGA’s inherent reprogrammability leads to area reduction compared to ASIC?” Yes, this is a reasonable question. You can reconfigure the entire chip by loading the full bitstream instead of loading partial bitstreams. But because the bitstream loading time is proportional to the size of the bitstream, the loading time of the partial bitstream is smaller than that of the full bitstream, which gives us an additional advantage.
Related Work
In the figure below, N similar-sized layers are time-multiplexed, resulting in 1/N resource usage or resulting in N times more parallelism. If partial bitstream loading time is negligible, the former approach maintains latency and throughput suffers to 1/N. The latter approach could result in some benefit in latency and potentially in throughput as well, but its bitstream loading times might not be negligible.
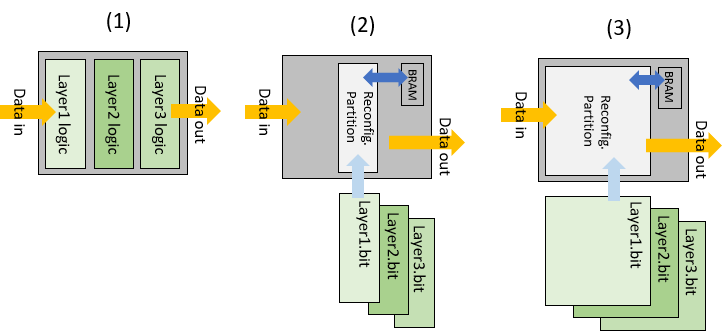
(1) is a design without PR. (2) time-multiplexes each layer, so compared to (1), it costs 1/3 resources. (2) may have similar latency for a single data with (1), but its throughput suffers. (3) has the 3-times size of layers of (1), which leads to more parallelism. However, as the size of reconfigurable block is too large, bitstream loading time must be an overhead.
Among some of the related works I found, [2] is a survey paper on PR(very comprehensive and educational!), and it suggests a dynamically evolving neural networks can utilize PR.
[3] introduces scenarios where PR achieves better throughput per a given area or better latency per a given area. It’s interesting how the authors interleave two PR regions to hide partial bitstream configuration time.
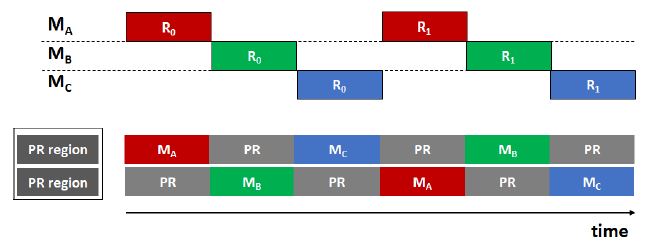
Figure is from [3]. While MA is computing, MB is loaded. While MB is computing, MC is laoded, and so on.
Nevertheless, [3]’s case study seems to be a little limited in a sense that the ASIC-style design can be improved. For instance, in the Table II in the paper, the module “cnn” is a bottleneck in the overall throughput. Then, can I allocate more resource on “cnn” and less on “lstm” which has a very high throughput of 271 fps?
[3] utilizes PR to use more area on each module, which leads to a better performance for each module. The authors use “batch” to amortize the partial bitstream loading time. If the batch size increases enough so that it’s much smaller than the module execution time, bitstream loading time, the main issue in time-multiplexed PR design, is negligible.
[4] fits a large DNNs on a small HW utilizing PR. [4] also uses batch to reduce the partial bitstream loading overhead. [5] is interesting because they keep the system busy by assigning loads to CPU when loading a new partial bitstream on FPGA. So, 4 convolutional layers are executed in FPGA->CPU(CPU is executing, and the next partial bitstream is being loaded)->FPGA->CPU fashion.
In conclusion, I was able to see some specific scenarios that PR is useful in NN application, like some module is a huge bottleneck[3] or a large network needs to fit in a relatively small FPGA[4]. To minimize the loading time of partial bitstreams, batching [3], [4] or SW-HW codesign[5] shows some potential.
References
- UG909: Vivado Design Suite User Guide: Partial Reconfiguration, Xilinx, Inc., 2100 Logic Drive, San Jose, CA 95124, April 2018. [Online]. Available: https://www.xilinx.com/support/documentation/sw_manuals/xilinx2018_1/ug909-vivado-partial-reconfiguration.pdf
- K. Vipin and S. A. Fahmy, “FPGA dynamic and partial reconfiguration: A survey of architectures methods and applications”, ACM Computing Surveys, Sep. 2018
- M. Nguyen, N. Serafin, and J. C. Hoe, “Partial Reconfiguration for Design Optimization”, FPL 2020
- M. Farhadi, M. Ghasemi, and Y. Yang, “A Novel Design of Adaptive and Hierarchical Convolutional Neural Networks using Partial Reconfiguration on FPGA”, IEEE High Performance Extreme Computing Conference, 2019
- F. K¨astner, B. Janßen, F. Kautz, M. H¨ubner∗ and G. Corradi, “Hardware/Software Codesign for Convolutional Neural Networks exploiting Dynamic Partial Reconfiguration on PYNQ”, IEEE International Parallel and Distributed Processing Symposium Workshops, 2018