
Hardware-Aware Neural Architecture Search
Neural Architecture Search(NAS) has gained huge attention since design space for CNN is vast and a handcrafted network with heuristics takes tremendous efforts. What’s more interesting is Hardware-Aware NAS(HW-NAS). Because one CNN architecture optmized for A device is not necessarily optimal for B device, people have studied NAS with the target HW platform in mind, HW-NAS.
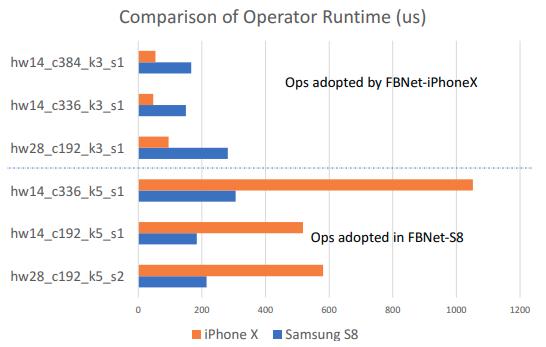
The upper three operators are faster on iPhone X, and the lower three operators are faster on Samsung S8 [1]

Experiments results from [2]; an architecture optimized for a specific device doesn't perform well on the other two devices
In HWNAS, people now optimize CNN not only for the accuracy but also for the latency for the target device. I’ve found that many studies adopt latency model instead of actually running on the device. The reasons behind are that 1)it’s slow to measure the actual latencies and feedback in the training phase, and 2)it’s cubersome to create such system.
Such latency models are convenient but could be inaccurate, and those without HW expertise may not be able to use them. Therefore, [2] creates a latency(also energy) database for HWNAS. The idea is to let people easily get the latency data just by querying it from the database they created by iterative measurement.
Thoughts
In [2], latency data for FPGA is based on HLS estimates, but HLS estimates are, in many times, inaccurate. What’s a bit more confusing is that what if I apply HLS PIPELINING or HLS UNROLLING pragma? Doesn’t this result in entirely different latency?
Development of CNN on HW accelerator is generally two steps: 1)find an architecture, and 2)implement on HW. Though I’m more of a hobbyist in this field, I’ve felt that 1) and 2) are tightly coupled; for instance, one architecture devised for a certain FPGA, is not mappable on a smaller FPGA because of lack of resources(a recent work tried to solve this problem and even created a framework to generate the final FPGA design [3]). This field seems to be full or research opportunities because the design space is intractable.
References
- B. Wu, X. Dai, P. Zhang, Y. Wang, F. Sun, Y. Wu, Y. Tian, P. Vajda, Y. Jia, and K. Keutzer, “FBNET: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture Search”, CVPR, 2019
- C. Li, Z. Yu, Y. Fu, Y. Zhang, Y. Zhao, H. You, Q. Yu, Y. Wang, and Y. Lin, “HW-NAS-Bench: HardWare-aware Neural Architecture Search Benchmark”, ICLR, 2021
- J. Ney, D. Loroch, V. Rybalkin, N. Weber, J. Kruger, and N. Wehn, “HALF: Holistic Auto Machine Learning for FPGAs”, FPL, 2021